Tipuri de arhitecturi hardware paralele
Pentru a putea discuta despre sistemele de gestiune a bazelor de date moderne este necesara o trecere sumara in revista asupra noilor concepte de arhitecturi hardware ce permit procesarea paralela sub diferitele ei aspecte.
Cele mai utilizate arhitecturi hardware paralele ce exploateaza multiple procesoare, memorii mari si mai multe unitati de disc sunt:
arhitectura 'Shared nothing' in care fiecare procesor detine propriile sale unitati de memorie si disc.
arhitectura 'Shared disks' utilizeaza multiple procesoare, fiecare cu unitatea sa de memorie dar cu sistem de disc partajat.
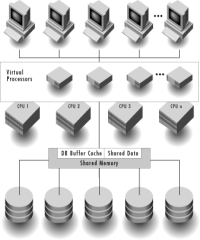
arhitectura 'Symmetric Multiprocessing' (SMP) utilizeaza procesoare multiple care detin in comun unitatile de memorie si disc.
In prezent, pentru a atinge performante ridicate din punctul de vedere al procesarii online a tranzactiilor (OLTP - 'Online Transaction Processing'), cele mai bune arhitecturi sunt considerate a fi cele uniprocesor si cele in multiprocesare simetrica (SMP). Pe de alta parte insa, sistemele paralele masive sau sistemele 'shared-nothing' sunt excelente pentru suport decizional pe scara larga. Arhitecturile in cluster, cum este si HACMP/6000 al companiei IBM, ofera insa alte avantaje, cum ar fi de exemplu inaltul grad de disponibilitate; daca un nod din cluster cade, un alt nod preia temporar sau definitiv lucrarile primului. Un al doilea avantaj este creat de faptul ca fiecare nod din cluster poate fi la randul sau o masina in multiprocesare simetrica, asigurand cluster-ului o scalabilitate mult mai mare. Prezentam in continuare cateva dintre facilitatile cele mai importante legate de lucrul in arhitecturi cluster luand drept exemplu pachetul software IBM HACMP/6000 destinat aplicatiilor care imbina performantele ridicate de executare a tranzactiilor cu lucrul in retele extinse eterogene, cu inalt grad de disponibilitate hardware si software.
HACMP/6000 Versiunea 2.1 - multiprocesare in cluster
Programul HACMP/6000 permite realizarea de arhitecturi in cluster, o forma de procesare paralela care distribuie lucrul intre mai multe resurse de procesare fara cresterea excesiva a overhead-ului de sistem asigurand in acelasi timp si un grad de scalabilitate bun in vederea unor extinderi viitoare ale configuratiei.
Pachetul de programe se compune din doua module de baza:
modulul HA ('High Availability') care detecteaza si recupereaza erori la nivelul dispozitivelor externe (discuri, cuploare de disc), al retelelor si adaptoarelor de retea, cat si la nivel de procesor. Daca un nod din cluster devine indisponibil, timpul de recuperare nominal realizat de modulul HA este cuprins intre 30 si 300 de secunde.
modulul CMP ('Cluster MultiProcessing') intra in actiune cand doua sau mai multe server-e acceseaza concurential acelasi subsistem de discuri. Accesul concurent la disc necesita insa suport la nivelul aplicatiei pentru mecanismul de blocare ('locking') si controlul accesului la date comune. HACMP/6000 utilizeaza doua modele de blocare a accesului concurential la discuri: modelul standard UNIX si mecanismul de blocare oferit de utilitarul de gestionare a blocarilor in cluster CLM ('Cluster Lock Manager') care permite sase tipuri de blocare, printre care mentionam blocarea asincrona si blocarea pe blocuri ce contin date globale.
Tipuri de resurse utilizate de HACMP/6000
Versiunea HACMP/6000 2.1 utilizeaza o metodologie de configurare flexibila care asociaza fiecare resursa cu un nod sau o adresa. Aceasta permite membrilor din cluster sa-si definesca resursele pe care le detin si pe cele pe care le preiau din diferite noduri.
Aceasta versiune defineste 2 tipuri de resurse:
w resurse proprietare: detinerea unei astfel de resurse denota o relatie directa intre un singur nod si acea resursa. Cand nodul proprietar este activ in cluster, resursa identificata apartine acelui nod. In configuratii cu acces concurent, o resursa mono-disc poate fi detinuta de mai multe noduri.
w resurse preluate: aceste resurse se leaga la un nod anume desemnat atunci cand nodul proprietar al resursei este detasat din cluster (devine indisponibil).
Configuratii 'High Availability'
Un mediu HA pentru aplicatiile complexe care necesita disponibilitate continua si fiabilitate foarte mare, poate fi configurat in mai multe moduri. Prezentam mai jos trei modele de configuratii posibile intr-un sistem cluster compus din doua masini Unix:
modelul 'hot standby or simple fallover' in care procesorul activ executa aplicatia si procesorul aflat in 'standby' asteapta o cadere a primului procesor. Masina 'standby' nu este neaparat in asteptare pasiva, ea putand prelua din sarcinile aplicatiei masinii primare, atunci cand capacitatea acesteia din urma este depasita.
modelul 'rotating standby' permite o configurare la fel ca cea anterioara cu deosebirea ca rolurile celor doua masini pot fi interschimbate.
modelul 'mutual takeover or partitioned workload': aceasta configuratie permite fiecarui procesor sa realizeze back-up pentru aplicatiile ruland pe oricare dintre procesoarele cluster-ului; configuratia realizeaza partitionarea datelor intre nodurile existente in cluster.
Pentru aplicatiile complexe cu misiune critica, pachetul de programe HACMP/6000 ofera urmatoarele facilitati:
reprezinta o alternativa la configuratia SMP asigurand o mai mare fiabilitate.
imbunatateste utilizarea masinilor mono-procesor asigurand scalabilitate fara inlocuirea resurselor hardware si software in configuratie 'mutual takeover'.
configuratia cu acces concurent la disc ( utilizand modulul HA) permite o inalta functionalitate si fiabilitate.
extinde posibilitatile unei instalari curente in configuratie 'mutual takeover', dubland efectiv capacitatea de procesare prin impartirea lucrului intre doua sau mai multe procesoare cuplate in cluster.
O mare parte dintre proiectantii de baze de date (Sybase, Informix, IBM DB2/6000, Progress) prefera sa ruleze programul HACMP /6000 in configuratii 'hot standby' sau 'rotating standby' pentru ca evita partitionarea in cazul unor baze de date foarte mari (fiecare masina din cluster are disc propriu si accesul la tabele situate pe alt disc se face numai prin retea) bazandu-se pe un model de arhitectura 'shared nothing'. Sistemul de gestiune Oracle a preferat insa modelul de arhitectura hardware 'shared disks' (cu partitionarea datelor).
Solitii de implementare
Procesarea paralela, definind doua sau mai multe procesoare ce executa procese concurente si actioneaza ca o singura unitate, permite rularea de aplicatii complexe sub sistemul UNIX. Cele mai multe dintre sistemele de gestiune a bazelor de date relationale sunt in prezent imbunatatite pentru a beneficia de procesarea paralela in sisteme eterogene, si a permite rularea de aplicatii complexe cu misiune critica. Compania de software care va veni cu un set de solutii optime pentru a integra bazele de date cu noile tehnologii de distribuire a datelor, va detine controlul asupra pietei in acest domeniu. Distribuirea optima a datelor este dificila din punct de vedere tehnologic, acest proces fiind puternic dependent de cerintele pentru asigurarea unui bun timp de raspuns la cereri, asigurarea integritatii datelor, disponibilitate continua, interoperabilitate etc.
Sistemele de gestiune a bazelor de date moderne utilizeaza o serie de notiuni abstracte si strategii asociate pentru a putea indeplini cerintele aplicatiilor actuale. Tranzactia, de exemplu, (definita ca o colectie de operatii care asigura trecerea unei baze de date dintr-o stare consistenta logic in alta), poate fi utilizata si in cadrul datelor distribuite pentru a asigura in retea trecerea unor grupuri de date si operatii asociate de la un post client la server sau de la un server la altul. Cea mai mare parte dintre producatorii de sisteme de baze de date au creat monitoare de procesare a tranzactiilor (TP - 'Transaction Processing') ce reprezinta utilitare evoluate care gestioneaza tranzactiile distribuite in retele eterogene. Metoda de comunicatie standard intre monitoarele TP si sistemele de baze de date a fost acceptata ca fiind protocolul X/A ce face parte din grupul de standarde X/Open. In prezent, serverele Sybase System 10 si Oracle 7 suporta protocolul X/A, in timp ce Informix OnLine adera indirect la acest protocol printr-un produs auxiliar, Informix TP/XA.
Din punctul de vedere al asigurarii integritatii datelor in sisteme client/server distribuite, producatorii de software de gestiune a bazelor de date au abordat urmatoarele strategii:
w tehnica 'two-phase commit' prin care toate modificarile impuse de o tranzactie asupra unei baze de date sunt fie comise (executia tranzactiei este finalizata) fie sunt anulate, cu revenirea bazei de date in starea anterioara efectuarii tranzactiei. Aceasta strategie nu este adecvata pentru retelele eterogene complexe in care probabilitatea de cadere a unui nod este mare si nici pentru sisteme cu misiune critica. Ea este utilizata ca o cale de a asigura faptul ca toate server-ele detin copii identice ale bazei de date in orice moment.
w strategia de replicare a datelor este in prezent solutia adoptata de companiile Oracle, Sybase si Informix. Replicarea este un proces in cadrul caruia mai multe server-e detin mai multe copii identice ale unei baze de date. Strategia de replicare a datelor difera esential de 'two phase commit' prin aceea ca replicarea garanteaza identitatea copiilor bazelor de date distribuite numai in anumite momente sau sub anumite conditii. Tehnica de replicare a datelor utilizata de server-ul Oracle 7 este denumita 'Table Snapshots', prin care server-ul central ('master') copiaza la anumite momente de timp definite, numai acele parti din baza de date care s-au modificat, propagand apoi aceste modificari in retea. Mecanismul de replicare utilizat de server-ul de baze de date Informix este similar metodei 'snapshots' utilizata de Oracle. Informix utilizeaza fisiere 'log' de 'backup' pentru a determina datele din tabelele bazei de date ce trebuie replicate (care contin modificari).
Serverele de replicare reprezinta numai inceputul unei intregi generatii de produse software care implementeaza concepte abstracte referitoare la distribuirea datelor in medii eterogene impreuna cu tehnologii avansate de gestiune si procesare paralela, optimizata a tranzactiilor.
Informix-OnLine, o arhitectura scalabila dinamic (DSA)
Compania Informix, a realizat o reproiectare completa a sistemului sau, introducand facilitati de multiprocesare simetrica (SMP).
In situatiile in care serverul Informix versiunea 6.0 a utilizat procesarea paralela, performantele au crescut in comparatie cu arhitecturile mai vechi. De exemplu, compania AT&T Network, un mai vechi client Informix, a fost impresionata de versiunea 6.0 creata in 1993. Utilizand vechea versiune 5.0 a server-ului Informix, timpul de realizare a unui index in baza de date era de 6 ore, pe cand cu versiunea 6.0 acest timp s-a redus la 30 de minute. Desi nu s-au imbunatatit toate operatiile efectuate in bazele de date, procentul mediu de timp castigat este de aproximativ 25. Pentru administratorii de sistem care considera procedurile de 'backup' cea mai serioasa problema, lista redusa de operatii in procesare paralela oferita totusi de server-ul Informix 6.0 a reusit sa rezolve mare parte din problemele legate de accesarea concurentiala. Versiunea de server Informix 6.0 a permis paralelism numai pe anumite operatii (creare de indecsi, sortari, backup, recuperare de date) si ruleaza pe unele platforme de multiprocesare simetrica (SMP).
In acest an a fost implementat serverul Informix-OnLine/DSA ('Dynamic Scalable Architecture') versiunea 7.0 a carui arhitectura scalabila poate gestiona scanari, unificari (join), sortari si interogari paralele pe bazele de date. In evolutia sistemelor Informix OnLine se desprind trei faze ce includ urmatoarele versiuni:
Informix-OnLine/DSA
DSA/PDQ ('Parallel Database Query')
DSA/XMP ('Extended Massively Parallel')
Informix-OnLine/DSA
Arhitectura DSA permite o multi-procesare flexibila orientata pe 'multithreading' atat pentru medii de procesare OLTP cat si pentru sisteme de luare de decizii ('Decision Support System' - DSS).
In medii OLTP, un numar mic de procese pe server pot gestiona eficient sesiuni utilizator multiple. Intr-un mediu DSS, o sesiune mono-utilizator poate sa detina mai multe cai de control al executiei care ruleaza in paralel utilizand eficient resursele hardware.
Informix-OnLine/DSA/PDQ
Aceasta versiune de arhitectura elaborata in 1994, transforma o singura operatie pe baza de date intr-un set de operatii paralele, ceea ce reduce substantial timpii de procesare pentru operatiile de tip OLTP si DSS atat timp cit mai multe procesoare lucreaza pentru o singura tranzactie. DSA/PDQ ruleaza pe arhitecturi SMP strans cuplate si are in vedere medii ca OLTP, DSS, Online Complex Processing (OLCP) sau procesarea in loturi.
Informix-OnLine/DSA/XMP
Aceasta versiune Informix cu procesare paralela masiva este programata pentru finalizare in 1995 si va rula pe arhitecturi slab cuplate ('loosely coupled') si arhitecturi MPP ('Massively Parallel Processing'). DSA/XMP poate beneficia de avantajele oferite de multiprocesarea distribuita in cluster-e cum ar fi programul HACMP/6000 ('High Availability Cluster Multiprocessing') oferit de compania IBM.
Oracle - Tehnologii de procesare paralela
Compania Oracle a implementat in 1994 versiunea 7.1 a sistemului sau de gestiune Oracle7. Serverul paralel Oracle7 realizeaza un echilibru mai bun intre necesitatile de multiprocesare si o mai buna administrare de sistem. Atat Informix cat si Sybase necesita partitionarea speciala a discurilor in procesarea paralela, spre deosebire de Oracle care considera ca sistemul sau este superior celorlalte doua din acest punct de vedere. Sistemul Oracle7 versiunea 7.1 mentine automat mai multe copii ale acelorasi date pe mai multe server-e, ceea ce elimina necesitatea unei munci laborioase de partitionare a discurilor. O critica adusa de celelalte companii (Informix, Sybase) afirma ca Oracle7 utilizeaza resursele sistemului de operare, cum ar fi semafoarele, pentru a permite multiplelor procese sa negocieze accesul, nedetinand de fapt o multiprocesare pe cai separate de executie in adevaratul sens. Deci din acest punct de vedere se afirma ca serverul Informix ar avea un potential mai ridicat pentru performante inalte decat omologul firmei Oracle.
Noile optiuni de interogare paralela in serverul Oracle7 vor permite masinilor ce lucreaza in multiprocesare simetrica (SMP), in multiprocesare in cluster-e si procesare paralela masiva (MP) sa execute o singura cerere (tranzactie) pe mai multe unitati de prelucrare (CPU) asigurand astfel o scalabilitate aproape liniara cu fiecare procesor adaugat in configuratie.
Server-ul paralel Oracle7 (OPS)
OPS a fost implementat si sub pachetul de programe IBM HACMP/6000 pe sisteme IBM - SPx (masini SP1 si SP2 cu procesare paralela bazate pe arhitectura RISC) si permite mai multor instante ale server-ului de baze de date Oracle sa ruleze concurent si independent. Fiecare instanta ruleaza in propriul sau nod de procesare si in propria zona de memorie partajata ('Shared Global Area Memory') avand un set propriu de procese Oracle7 in 'background' (monitorul sistemului, monitorul de proces, scrierea in baza de date, etc.) utilizate la backup si la regasirea datelor in situatii de cadere a sistemului. Aceleasi fisiere ale bazei de date sau fisierele de gestiune pot fi accesate de oricat de multe instante ale server-ului Oracle7.
Toate instantele de server Oracle7 pot executa tranzactii in mod concurential asupra aceleiasi baze de date dand posibilitatea utilizatorilor sa beneficieze de puterea de procesare a mai multor unitati de prelucrare.
Din punctul de vedere al utilizatorului, mediul paralel Oracle isi ascunde complet paralelismul. Deoarece softwareul de server Oracle utilizeaza aceeasi interfata SQL in toate bazele de date ale sistemului, utilizatorul interactioneaza numai cu server-ul de baze de date Oracle standard. Paralelismul nu adauga nici comenzi noi si nici extensii la cele standard, optimizarea resurselor si gestionarea paralela realizandu-se automat.
Serverul Oracle 7.1 in sisteme cluster
Intr-un sistem cluster configurat cu programul HACMP/6000 (sistem de tipul 'shared-disk') si lucrand in modul de acces concurential, server-ul paralel Oracle permite diferitelor noduri din cluster sa imparta aceeasi aplicatie. Aceasta facilitate depaseste bariera de performanta a sistemelor de gestiune a bazelor de date relationale (SGBDR) in sistem uniprocesor.
Pentru cresterea performantelor in cluster-e HACMP/6000, server-ul paralel Oracle7 utilizeaza o gestiune paralela a memoriei cache facilitata de modulul de administrare a blocarilor in mediu distribuit ('Distributed Lock Manager' - DLM) al cluster-ului. Fiecare nod din cluster detine un cache local continand acele blocuri din bazele de date care au fost recent accesate de tranzactii ruland in acel nod.
Pentru reducerea timpului de raspuns la cereri complexe pe mai multe tabele mari, anumite operatii de sortare, scanare, unificare sunt realizate in tehnologie paralela utilizand optiunea de cereri paralele a server-ului Oracle 7.1 pe masini IBM SPx. Prin scanarea paralela, nodurile lucreaza simultan pentru a cauta in diverse tabele ale bazei de date, reducandu-se astfel cantitatea de lucru pe fiecare nod in parte si obtinandu-se o crestere substantiala a performantelor. Unificarea paralela permite mai multor noduri scanarea de tabele separate, urmata apoi de unificarea selectiilor in paralel pentru a furniza rapid raspunsul final. Sortarea paralela imparte datele in mai multe transe astfel incat fiecare nod sa sorteze o mica parte din date, dupa care nodurile colaboreaza pentru a combina rapid listele partiale sortate intr-un rezultat final.
In sisteme paralele masive (cum sunt si masinie IBM SPx) care utilizeaza un mare numar de procesoare ce lucreaza la indeplinirea aceleiasi cereri, scanarea, unificarea si sortarea se executa in paralel, performantele de executie ale tranzactiilor complexe imbunatatindu-se substantial.
Oracle 7.1 - incarcare paralela de date si indexare paralela
Server-ul Oracle 7.1 utilizeza facilitatea de incarcare paralela ('Parallel Direct Load') in tabele a datelor externe nestructurate. Incarcarea paralela directa permite utilizatorilor lansarea din mai multe noduri a proceselor de incarcare concurente multiple legate de acceasi tabela. Incarcarea paralela utilizeaza multe resurse (discuri, benzi) pentru a transfera simultan datele in aceeasi tabela din mai multe surse. Odata datele incarcate, crearea indexului poate fi divizata pe mai multe noduri server. Daca tabela de baza este intinsa pe mai multe fisiere de baze de date situate in mai multe noduri de procesare, indexarea paralela se realizeaza automat. Dupa scanarea paralela a tabelei de baza realizata asupra tuturor fisierelor de date, tabela de baza este impartita in partitii, fiecare partitie continand cheile tabelei de baza reprezentind o parte din intregul domeniu de chei de indexare. Crearea unui index pentru fiecare partitie se realizeaza simultan, acesti indecsi fiind eventual unificati intr-un singur index permanent.
Oracle 7.1 - copierea si recuperarea paralela a datelor
Utilitarul Oracle7.1 'Parallel Backup/Restore' si utilitarul de recuperare paralela a datelor pot reduce drastic timpul de copiere, de refacere si recuperare a datelor pentru baze de date mari, de ordine de marime cuprinse intre zeci si sute de gigabytes. Aceste utilitare Oracle 7.1 sunt disponibile si pe masini IBM - SP2 (medii de tip 'shared nothing') si permit copierea paralela online a multiplelor fisiere de date, pe diferite medii externe. Aceasta este o alternativa mai robusta la mai lentele si mai putin fiabilele utilitare de backup UNIX 'dd', 'cpio' si 'tar'. Odata ce restaurarea datelor este realizata, poate fi aplicata recuperarea paralela ce permite citirea fisierelor 'log'.
Sybase - Build Monumentum
Compania Sybase a facut un pas major in proiectarea de sisteme de baze de date din noua generatie introducand pe piata un produs ce permite utilizatorilor de calculatoare Macintosh si celor bazate pe sistemul Windows facilitati de lucru in 'multithreading'. Sybase Build Monumentum ruleaza in procesare pe mai multe cai de control ale executiei atat pe platforme Windows NT cat si pe platforme Unix, adaugand in acelasi timp pe arhitectura existenta facilitati de lucru cu baze de date orientate pe obiect. Multiprocesarea in retele distribuite este realizata insa numai din punct de vedere 'client'; Build Monumentum detine un administrator care gestioneaza procese in 'multithreading' chiar daca sistemul de operare gazda nu suporta in mod normal acest mod. Situat in gama de intrare a SGBDR, Build Monumentum este considerat de specialisti ca fiind un produs mai reusit decat produsele din acceasi gama ale companiilor Oracle sau Informix.
Sybase System 10
Familia de produse software Sybase System 10 se situeaza in gama medie de SGBDR ce ruleaza in medii client/server distribuite.
De la fondarea companiei din 1984, Sybase a adus in SGBDR doua tehnologii cheie: arhitectura client/server si performantele OLTP. Aceasta a insemnat dezvoltarea de interfete API ('Application Programming Interface') si implementarea noilor concepte de server 'multithreaded', proceduri compilate partajate, trigger-e si apeluri de proceduri RPC ('Remote Procedure Calls') client/server si server/server.
Sybase Open Client si Open Server
Sybase SQL Server 10 este o componenta a sistemului Sybase System 10 si la ora actuala este inca singurul produs de gestiune a bazelor de date care a integrat lucrul in retea cu ambele interfete API client si server. Toate produsele Sybase sunt construite in SYBASE Open Server si Open Client care reprezinta o interfata API pentru lucrul in retea si cu facilitati de 'multithreading' proiectata pentru aplicatii de inalta performanta in medii client/server distribuite.
Interfetele Open Client si Open Server (utilizate pe scara larga in mediile industriale) suporta atat comunicatii via SQL cat si RPC intre statii client si statii server sau intre servere. Aceste interfete ruleaza sub o mare varietate de protocoale si de biblioteci de retea. Arhitectura client/server Sybase este bazata pe conexiuni 'multithreaded' care permit atat comunicatii sincrone cat si asincrone.
Sybase SQL Server in sisteme uniprocesor si SMP
Server-ul Sybase SQL este nucleul de baza al lui System 10 pentru procesare in 'multithreading' in cadrul unei retele eterogene. Utilizand un model optimizat de procesare pe mai multe cai de control ale executiei, server-ul SQL poate gestiona simultan in cadrul unui singur proces un mare numar de utilizatori. Un utilizator client ce acceseaza server-ul SQL prin interfata Open Client, necesita mai putin de 50 Kbytes de memorie pe server. Server-ul SQL este optimizat pentru standardul de performanta OLTP; la sfarsitul anului 1993, Sybase si IBM au realizat un 'benchmark' prin care la un server SQL aflat pe un sistem RISC/6000 Model 990 s-au atasat 2760 de utilizatori clienti iar timpul mediu de raspuns a fost de 0,79 secunde. Server-ul Sybase SQL a fost primul care a utilizat cod compilat/partajat atat pentru gestionarea bazelor de date locale cat si pentru trimiterea de apeluri de proceduri RPC la alte server-e aflate la distanta.
Server-ul Sybase SQL detine multe facilitati pentru lucrul in sisteme cu disponibilitate inalta. In cadrul sistemului Sybase System 10, server-ul SQL include un proces server separat de backup care permite copierea online fara impact asupra performantelor serverului. Serverul de backup poate copia la mai multe dispozitive externe simultan pana la 10 gigabytes pe ora si poate opera pe o masina separata pentru a permite server-ului OLTP sa ruleze neafectat in timpul procedurii de backup.
Server-ul Sybase SQL in sisteme cu multiprocesare simetrica
Pentru sistemele cu multiprocesare simetrica (SMP), compania Sybase a realizat o implementare multiproces prin care mai multe servere SQL sunt incarcate in memorie iar unitatile centrale de prelucrare raman dedicate complexului de servere. Serverele SQL comunica utilizand memoria partajata si repartizeaza 'thread'-urile intr-o coada de executie care cauta urmatorul procesor disponibil. Arhitectura rezultata prezinta un inalt grad de scalabilitate in medii client/server eterogene.
Server-e paralele Sybase
Server-ul de replicare permite utilizatorilor sa creeze copii primare si replicate ale datelor asigurand distribuirea fault-toleranta a tranzactiilor de la copiile primare la cele replicate. Server-ul de replicare utilizeza un protocol 'store and forward' pentru a asigura distribuirea continua a tranzactiilor intre posturile de replicare. Server-ul de replicare utilizeaza un subproces care permite posturilor replicate sa primesca in mod continuu sau la anumite intervale de timp actualizari ale datelor la nivel de linie, coloana, tabela sau la nivel de functii definite de utilizator.
OmniSQL Gateway permite oricarei aplicatii client sa acceseze in mod transparent surse de date multiple si eterogene ca si cum acestea ar fi localizate intr-o singura baza de date. OmniSQL Gateway permite accesul la date intr-o mare varietate de formate: SYBASE, DB2, Oracle, Ingres, Informix, etc.
Server-ul de navigare cupleaza impreuna mai multe server-e SQL intr-o arhitectura paralela bazata pe mesaje pentru a permite copierea paralela, performante OLTP paralele, procesarea paralela a cererilor si implementarea altor utilitare paralele pentru aplicatii care necesita baze de date mari, un mare numar de utilizatori si tranzactii complexe.
Server-ul de navigare Sybase utilizeaza cate un server SQL pe fiecare nod, intr-o arhitectura 'shared-nothing' cu datele partitionate integral. Pentru un post client, server-ul de navigatie arata ca un singur server SQL mare ce permite aplicatiilor sa exploateze puterea unui sistem paralel extins ca si cum ar fi o masina cu un singur nod. Server-ul de navigare este planificat sa devina disponibil pe piata ruland sub sisteme IBM din familia SPx la inceputul anului 1995.
Sybase si IBM HACMP/6000 pentru arhitecturi in cluster
Server-ul de replicare Sybase permite in prezent implementarea de aplicatii cu performanta OLTP ridicata intr-un nod de cluster HACMP/6000, in paralel cu replicarea tranzactiilor catre un al doilea sau al treilea nod de cluster. Aceasta permite aplicatiilor client situate in nodul OLTP sa primeasca raspunsuri intr-un timp predictibil garantat, fara ca nodul sa fie afectat de cereri si rapoarte periodice. Functiile de suport decizional sunt automat directionate de catre interfata Open Client la un al doilea nod de cluster, ele neafectand aplicatiile cu misiune critica.
Intr-un cluster HACMP cu doua sau mai multe noduri, fiecare nod opereaza independent, astfel incat nu exista overhead suplimentar generat de utilitarul de gestionare a blocarilor (DLM - 'Distributed Lock Manager'). Toate masinile din cluster pot rula eficient si la deplina performanta a unitatilor de prelucrare individuale. Daca un nod din cluster cade, programul HACMP/6000 pune automat aplicatia OLTP pe un alt nod, mutand in background aplicatiile de suport si decizie.
IBM DB2 - Parallel Edition
Compania IBM dezvolta in prezent sistemul sau de gestiune a bazelor de date relationale, DB2/6000, intr-o arhitectura paralela multi-procesor cu suport hardware mergand de la retele locale de sisteme uniprocesor RISC System/6000 si pana la sisteme paralele IBM POWER SPx. Server-ul paralel de baze de date DB2 Parallel Edition poate manipula eficient baze de date foarte mari utilizand strategii de partajare a datelor si executare paralela de cereri asupra acestora.
Sistemul de gestiune DB2/6000 se extinde in prezent pentru a suporta o arhitectura 'Shared nothing', selectata din doua motive:
este o arhitectura scalabila pana la nivel de sute de procesoare
ofera portabilitate ridicata deoarece necesita o singura legatura de comunicatie intre procesoare, deci poate fi portata pe orice tip de platforma.
Noua versiune a sistemului de gestiune DB2/6000 se proiecteaza pentru a suporta si o arhitectura SMP ('Symmetric Multiprocessing').
Server-ul DB2 Parallel Edition, cuplat cu programul HACMP/6000 intr-o arhitectura cluster cu masini RISC System/6000 furnizeaza accesul concurent al tuturor procesoarelor la o singura baza de date.
Intr-o arhitectura 'shared nothing' cu implementarea paralela a sistemului de gestiune DB2 intr-o o retea de masini IBM RISC/6000, stocarea unei baze de date se realizeaza intr-o retea de procesoare care furnizeaza buffer-e, structuri de blocare, fisiere de log si discuri separate pentru fiecare procesor in parte. Aceasta structura previne disputarea concurentiala a memoriei cache rezultand din faptul ca toate procesoarele partajeaza acelasi set de resurse.
Pentru a minimiza comunicatia intre procesoare, operatorii relationali sunt executati pe procesorul ce contine datele asupra carora se executa respectivii operatori, ori de cate ori acest lucru este posibil. In consecinta nu este necesara implementarea unui utilitar de gestionare a blocarilor la nivel global, deoarece fiecare procesor extrage un raspuns partial din partea sa de baza de date sau de tabela. La intervale regulate de timp, un detector global de 'deadlock' analizeaza blocarile iar in cazul cand detecteaza o asemenea blocare, el selecteaza un nod sau un proces 'victima' pentru a rezolva problema.
In arhitecturi cu multiple noduri de procesare, pentru baze de date mari, plasarea datelor devine o problema complexa si administrarea de sistem poate fi dificila. Implementarea paralela a sistemului DB2 utilizeaza un limbaj de definitie a datelor si utilitare de administrare necesare partitionarii datelor. DB2/6000 asigura doua facilitati importante pentru partitionarea tabelelor de baze de date mari: utilizarea de chei de partitionare si de grupuri de noduri:
pentru o baza de date ce contine multe tabele, utilizatorul ce dezvolta aplicatia poate sa defineasca o cheie de partitionare pentru fiecare tabela.
intr-o configuratie hardware 'shared nothing' (cum ar fi de pilda familia de masini IBM SPx sau statii conectate in retele locale), fiecare procesor ruleaza echivalentul unui sistem de baze de date DB2/6000 cu un singur nod. Tabelele bazei de date pot fi definite de-a lungul unui set de noduri grupate avand un identificator unic si fiind delimitat peste un anumit numar de procesoare. Deci un grup poate sa contina unul sau mai multe procesoare iar fiecare procesor poate fi membru in mai multe grupuri in cadrul aceleiasi baze de date sau in baze de date diferite. Pe masura ce marimea tabelelor creste sau numarul de procesoare in sistem se mareste, se pot adauga procesoare unui grup existent utilizand propozitii ale limbajului de definitie a datelor; dupa adaugarea unui nou procesor, utilitarul de reechilibrare ('rebalance') al sistemului DB2 asigura redistribuirea datelor in noua structura.
Prezentam pe scurt urmatoarele caracteristici ce permit o gestionare eficienta a sistemului DB2 Parallel Edition:
vederile create pe tabele sunt separate de plasarea fizica a datelor in sistem
datele pot fi distribuite peste mai multe discuri pentru a reduce gatuirile provocate sistemului de intrare/iesire.
pe masura ce marimea bazelor de date creste se poate mari si numarul de procesoare din sistem.
DB2 Parallel Edition - procesarea cererilor paralele
DB2 Parallel Edition genereaza o strategie de executie paralela pentru toate propozitiile SQL, prin intermediul unui utilitar de optimizare, bazata pe formule de minimizare a costului de executie a bazelor de date relationale. Dupa compararea catorva strategii de executie paralela pentru o propozitie SQL data, acest utilitar de optimizare alege strategia cea mai eficienta pentru respectiva propozitie. O propozitie SQL de tipul 'select', 'insert', 'update' sau 'delete' este impartita in mai multe task-uri separate care executa cate o parte din cerere si colaboreaza la furnizarea raspunsului final. Generarea de strategii paralele de executie pentru o propozitie SQL data este un proces automat. Un program de aplicatie ce utilizeza DB2/6000 nu trebuie sa fie recompilat pentru a exploata executia paralela. Cand programul de aplicatie este legat la o baza de date paralela, se genereaza si se stocheaza la cerere strategia adecvata de executie paralela.
Strategiile paralele utilizate de DB2/6000 includ scanari paralele de tabele, scanari de indecsi paraleli; unificari redirectate prin mecanism de 'hashing', unificari redistribuite (folosite atunci cand nici una din tabele nu este partitionata dupa coloanele pe care se face unificarea), etc.
DB2 Parallel Edition - utilitare de procesare paralela
DB2 Parallel Edition furnizeaza mai multe utilitare de baza in gestiunea paralela a bazelor de date: utilitarele de incarcare a datelor si utilitarul de reechilibrare, crearea paralela de indecsi, utilitar de backup/restore, redistribuirea liniilor unei tabele pe disc, recuperarea datelor.
incarcarea datelor in tabele se poate realiza fie prin utilitarul de import DB2/6000 fie utilizand utilitarele de incarcare rapida 'Bridge Fastload' sau programul optional DB2 de 'fast-load'. Sistemul DB2 Parallel Edition furnizeaza operatii de inserare imbunatatite prin care liniile sunt preluate in loturi si transmise astfel procesorului de destinatie. Aceasta facilitate este implementata ca o optiune la momentul legarii, multe programe putand sa o utilizeze fara modificari.
O alta modalitate de incarcare este crearea directa a bazelor de date fara a folosi un mecanism de lucru cu operatii 'insert'. Intr-o baza de date paralela, cea mai buna abordare este partitionarea fisierului de date de intrare bazata pe valorile definite pentru cheile de partitionare. Se creaza astfel cate un fisier de intrare pentru fiecare procesor care va stoca tabela respectiva. Apoi partitiile sunt incarcate in paralel la toate procesoarele din retea. Interfata API care faciliteaza acest proces de incarcare determina alocarea liniilor tabelei la procesoare in functie de valorile cheilor de partitionare si numele grupului de noduri.
Utilitarul de rebalansare incorporeaza o functie hash predefinita care determina valoarea cheii de partitionare a unei linii dintr-o tabela si procesorul pe care este stocata aceasta linie (procesorul selectat fiind din grupul de noduri in care a fost creata tabela). Acest utilitar asigura uniformitatea distribuirii datelor intre noduri si in cadrul grupurilor de noduri. Reechilibrarea datelor este realizata online (nu este necesara oprirea sistemului) la nivel de grup de noduri prin reechilibrarea tuturor tabelelor continute in acel nod.
DB2 Parallel Edition permite crearea de indecsi unici in care coloanele cheie contin cheile de partitionare sau indecsi multipli in care aceste coloane sunt disjuncte. Crearea de indecsi este realizata in paralel la toate procesoarele. Pentru fiecare partitie a unei tabele stocata intr-un nod, se creaza un index local.
Utilitarul de backup/restore poate fi apelat de catre fiecare procesor in parte pentru copierea segmentului de baze de date aflate in acel nod. Copierea datelor se poate face in paralel la mai multe procesoare, dar aceasta manevra necesita resurse fizice mari (mai multe disc-uri la fiecare procesor).
