|
Arhitecturi pentru Semnale Multidimensionale
Arhitecturi de codare video
In lucrarea de fata ne propunem prezentare unor notiuni fundamentale legate de compresia semnalului video. In prima parte sunt prezentate principiile care stau la baza reducerii redundantei din semnalul video. Se vor analiza diferitele tipuri de redundanta si se vor prezenta cateva metode pentru codarea informatiei. In partea a doua a lucrarii vom prezenta arhitectura standardului MP EG. In partea a treia a lucrari vom face simulari pentru compensarea de miscare si vom compara diversi algoritmi.
Compresia digitala a fisierelor video este esentiala in transmisiile gen teleconferinte pe Internet, televiziune in format High Definition (HDTV) sau comunicatii prin satelit. De asemenea este esentiala pentru a putea stoca informatia preluata pe diverse medii de stocare datorita limitari capacitati de stocare a acestora.
Pornind de la teoria lui Shanon, informatia poate fi reprezenta in format binar. Astfel rata de transmisie a bitilor a fost stabilita in functie de parametrii sistemelor hardware (marimea imagini, rezolutia respective rata de scanare, rata de refresh). Incepand de la cel mai jos nivel compresia apare in momentul atunci cand se analizeaza un semnal video aparut la intrare, iar informatia care nu este importanta pentru observatorul uman este inlaturata. Apoi fiecarui eveniment aparut la intrare ii este asociat un cod. Lunginea fiecarui cod asociat unui eveniment depinde de numarul de aparitie a acestui evenimet in cadrul informatiei astfel: daca evenimentul este unu care o rata de aparitie foarte mare atunci codul va fi alcatuit dintr-un numar redus de biti, iar in cazul cand evenimentul are o rata de aparitie foarte mica codul este alcatuit dintr-un numar mare de biti.
In mod usual exista patru metode de compresie video si anume[9]:
Transformata Cosinus Discreta (DCT);
Cuantizarea Vectoariala (VQ);
Transformata Wavelet Discreta (DWT);
Compresia Fractal.
Redundanta spatiala reprezinta o corelatie statistica intre pixelei dintre imagine, ea mai fi numinta si redundanta interframe.
Este binecunoscut faptul ca in esantionarea semnalului TV coeficientii de autocorelatie normalizati de-a lungul unui rand sunt shiftati cu un pixel, fiind mult mai aproape de valoarea maxima 1. Aceasta este intensitatea pixelului de-a lungul randului shiftat cu o pozitie.
Acest lucru nu este un fapt surprinzator deoarece in cadrul unei imagini intensitatea se modifica de la pixel la pixel exceptand regiunile marginale.
Redundanta temporala se concentreaza asupra comportamentului pixelilor din frame-uri successive din cadrul unei secvente video, fiind cunoscuta si sub denumirea de redundanta intraframe.
Daca se considera o camera care preia imagini 2D, si daca intervalul de timp intre achizitiile de imagine este mic se poate observa ca imaginea curenta preluata are parti commune cu imaginile preluate anterior.

Figura 1.
Imagini cu parti redundante.
De aceea au fost dezvoltate tehnici de predictie a imagini urmatoare bazate pe vecini. Prin eliminarea acelor parti comune mai multor imagini, parti redundante, se micsoreaza dimensiunea cadrului de informatie care permite o transmisie mult mai rapida, o stocare mult mai eficienta, aceasta micsorare realizandu-se prin intermediul tehnici de compresie predictive.
Redundata psihoviziuala se refera cu precadere la caracteristici organului vizual uman si anume pe faptul ca raspunsul stimulilor vizuali nu se poate descrie cu ajutor unei functi liniare. Ca un exemplu ne putem referi la imaginile color unde diferenta de crominata din carul unei culori este sesizata mai greu de catre ochi la fel intamplandu-se si in cazul intensitati unei imagini. Astfel bazandu-se pe aceata tehnica in care unele amanunte din imaginei nu sunt atat de importante pentru HVS (human visual system) se pot inlatura si pot duce la comprimarea imgini rezultand o compresie a redundantei psihovizuala.
Dupa cum s-a putut observa redundanta intre pixeli se concentreaza pe corelatia dintre pixeli. Redundanta psihovizuala se refera la informatia redundanta psihovizuala la care HVS nu este sensibil. Deci este clar ca atat redundanta intre pixeli cat si cea psihovizuala sunt asociate cu o anumita cantitate de informatie continuta in imagine cat si in video.
Eliminarea redundantei sau utilizarea acestei corelati prin utlizarea unui numar de biti mai mic pentru reprezentarea informatiei rezulta astfel procesul de codarea a imagini sau video. In acest fel redundanta informatie nu are nici o legatura cu reprezentarea informatiei. Pentru a fi mai clar se pot analiza urmatoarele exemple.
|
Simbol |
Probabilitate de aparitie |
Cod 1 |
Cod 2 |
|
a1 |
|
|
|
|
a2 |
|
|
|
|
a3 |
|
|
|
|
a4 |
|
|
|
|
a5 |
|
|
|
In prima coloana sunt listate 5 simboluri diferite care trebuie sa fie codate. Cea de-a doua coloana contine probabilitatile de aparitie a acestor 5 simboluri. Cea de-a treia coloana contine codurile 1, nu este altceva de cat un set ce cuvinte cod obtinut prin utilizarea alinieiri uniforme pe lunginea civinteleor de cod. Cea de-a patra coloana contine lunginea variabila de cod. Este oare cum evident ca acel simbol a acel simbol a carui probabilitatea de aparitiei este ce a mai mare va fi codat cu cu un numar de biti mai mic. Ca o comparative se poate observa intre cele 2 metode codare ca cea de-a doua este cu mult mai eficienta prin prisma utlizari unei tehnici de calcula mediei lungimi cuvintelor de cod, obtinandu-se o codare mulgt mai eficienta decat prima in care se utilizeaza o cadate binar naturala.
Entropia H de ordinul intai a unei surse discrete fara memorie, continand L simboluri, este definita astfel :
![]()
unde pi
este probabilitatea de aparitie a
simbolului de ordin i. Entropia
sursei se masoara in biti/simbol, si este marginita inferior de lungimea medie
a cuvantului de cod necesar pentru a reprezenta simbolurile sursei. Aceasta
margine inferioara poate fi obtinuta daca lungimea cuvantului de cod pentru
simbolul i este aleasa a fi -![]() biti astfel incat sunt desemnate cuvinte de cod mai scurte
pentru simboluri mai probabile si cuvinte de cod mai lungi pentru simboluri mai
putin probabile. Desi valoarea -
biti astfel incat sunt desemnate cuvinte de cod mai scurte
pentru simboluri mai probabile si cuvinte de cod mai lungi pentru simboluri mai
putin probabile. Desi valoarea -![]() biti/simbol poate sa nu fie obtinuta practic deoarece -
biti/simbol poate sa nu fie obtinuta practic deoarece -![]() poate sa nu fie
intreg, ideea unei lungimi de codare variabile, care sa reprezinte simbolurile
cel mai frecvent aparute utilizand cuvinte de cod mai scurte si simbolurile mai
putin frecvente utilizand cuvinte de cod mai lungi, poate fi aplicata pentru a
obtine compresia de date. Algoritmii de compresie a datelor care utilizeaza
datele statistice ale sursei pentru a obtine rata de biti/simbol apropiata de
valoarea entropiei sunt cunoscuti in general ca algoritmi de codare entropica.
Codarea entropica este lipsita de pierderi deoarece datele initiale pot fi
reconstruite exact utilizand datele compresate.
poate sa nu fie
intreg, ideea unei lungimi de codare variabile, care sa reprezinte simbolurile
cel mai frecvent aparute utilizand cuvinte de cod mai scurte si simbolurile mai
putin frecvente utilizand cuvinte de cod mai lungi, poate fi aplicata pentru a
obtine compresia de date. Algoritmii de compresie a datelor care utilizeaza
datele statistice ale sursei pentru a obtine rata de biti/simbol apropiata de
valoarea entropiei sunt cunoscuti in general ca algoritmi de codare entropica.
Codarea entropica este lipsita de pierderi deoarece datele initiale pot fi
reconstruite exact utilizand datele compresate.
Cand este cunoscuta distributia de probabilitati a unei surse discrete, algoritmul de codare Huffman furnizeaza o procedura sistematica de proiectare pentru a obtine lungimea optima a cuvantului de cod. Proiectarea codurilor Huffman implica 2 pasi: generarea simbolurilor si asignarea codurilor[7]. Acesti pasi sunt descrisi in continuare:
i. Cele doua noduri cu cele mai mici probabilitati converg si formeaza un nou nod cu probabilitatea egala cu suma probabilitatilor celor doua noduri.
ii. Se asigneaza "1" si "0" perechii de ramuri care converge intr-un nod.
Codul Huffman este unic decodabil. O data generat codul, procedura de codare poate fi realizata prin alocarea fiecarui simbol de intrare catre cuvantul de cod corespondent, care poate fi stocat intr-un tabel. Procedura de decodare include extragerea cuvintelor de cod dintr-un sir de cuvinte de cod concatenate si asignarea fiecarui cuvant de cod simbolului corespunzator, utilizandu-se respectivul cod Huffman. O proprietate importanta a codurilor Huffman este aceea ca nici un cod sau vreo combinatie de coduri nu reprezinta prefixul vreunui alt cod. Conditia de prefix permite extragerea cuvintelor de cod dintr-un cuvant de cod concatenat si elimina surplusul pozitiior transmise. Conceptual, cuvantul de cod extras poate fi obtinut bit cu bit prin transversalizarea arborelui de codare Huffman. Se incepe de la radacina arborelui; la fiecare nod intermediar, se ia o decizie in concordanta cu bitul receptionat, pana cand se ajunge la nodul terminal ; se gaseste , astfel, cuvantul de cod, iar bitii corespunzatori sunt extrasi din sirul de biti.
In codarea run-length, un sir de simboluri identice este reprezentat utilizand un indicator de lungime a simbolului si un indicator de valoare a acestuia. De exemplu, codul run-length pentru secventa de simboluri sursa este , unde valoarea ce are anterior simbolul # reprezinta indicatorul de lungime. Acesti indicatori de lungimile si de valoare a simbolurilor in run-length pot fi codati utilizand algoritmii de codare entropici. Pentru secvente binare, sirurile consecutive sunt formate din valorile alternate 1 si 0, aceste valori putand sa nu fie explicit prezentate. Astfel, doar simbolul de indicare a lungimii si prima valoare a intregii secvente sunt necesare in cazul codarii run-length pentru siruri binare[10]. De exemplu, secventa binara poate fi codata astfel: .
Pentru secventele de date corespunzand imaginilor digitale, exista simboluri cu o mare probabilitate de aparitie, care apar consecutiv, cum ar fi zeo-urile. In acest caz, doar aceste siruri de simboluri sunt codate run-length in simboluri intermediare, iar aceste simboluri intermediare, alturi de restul simbolurilor sursa originale, sunt codate apoi utilizand scheme de codare entropica. De exemplu, secventa poate fi mai intai codata run-length ca , unde a doua valoare din paranteza rotunda reprezinta valoarea numarului de simboluri succesive diferite de zero, iar prima valoare din paranteza rotunda indica numarul de simboluri anterioare consecutive zero.
Transformata cosinus discreta (DCT - Discrete Cosine Transform) a fost prima transformare introdusa pentru recunoasterea formelor prin prelucrarea imaginilor si pentru filtrarea Wiener [6]. DCT este o transformare ortogonala care "decoreleaza" semnalele intr-un singur bloc de imagine si compacteaza energia intregului bloc de imagine in cativa coeficienti DCT de frecventa joasa. Aceasta metoda este introdusa in ambele standarde de compresie video si a imaginii. Acest capitol introduce varianata simetrica unidimensionala 1-D DCT pentru secvente pare.
Consideram o secventa de N puncte x(n), astfel incat x(n)=0 pentru n<0 si pentru n>N-1. Transformatele-pereche DCT si IDCT (transformata inversa a DCT) pentru aceasta secventa sunt:
![]() (1)
(1)
![]() (2)
(2)
unde:
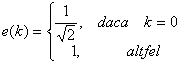 (3)
(3)
Transformata Wavelet este o transformare ortonormala multirezolutie [5]-[7]. Aceasta transformare descompune semnalul intr-o banda de energie care este esantionata cu diferite rate, care sunt determinate pentru maximizarea informatiei semnalului in timpul minimizarii ratei de esantionare sau a rezolutiei pentru fiecare sub-banda[8].
In cadrul analizei wavelet, semnalele sunt reprezentate utilizand un set de functii de baza (numite functii wavelet) obtinute prin deplasarea si scalarea unei singure functii prototip, denumita "functia wavelet mama", in timp. Transformata Wavelet unidimensionala discreta (DWT) pentru secventa x(n) este definita astfel:
![]() , pentru 0 i m-2
, pentru 0 i m-2
![]() , pentru i=m-1 (4)
, pentru i=m-1 (4)
unde versiunile deplasate si scalate ale functiei
" wavelet mama", h(n) , ![]() pentru
pentru
0 i m-1 si - k , sunt functii baza , iar yi(n) sunt coeficientii Wavelet. Transformata inversa poate fi calculata astfel :
![]() (5)
(5)
unde este desemnata astfel incat relatia (23) permita reconstruirea perfecta a semnalului original x(n). Se observa ca evaluarea transformatelor DWT si IDWT este similara operatiilor de convolutie. De fapt, transformatele DWT si IDWT pot fi calculate recursiv printr-o serie de convolutii si decimari si pot fi implementate utilizand bancuri de filtre.
Bancul de filtre digital este un ansamblu de filtre avand intrarea comuna (cind ne referim la banc de filtre de analiza) sau iesirea comuna Bancurile de filtre sunt folosite in general pentru codarea pe sub-benzi, unde un singur semnal x(n) este impartit in m sub-benzi cu bancul de filtre de analiza; in cazul bancului de filtre de sinteza, semnalele de pe cele m sub-benzi de intrare sunt combinate pentru reconstructia semnalului y(n).
Transformata discreta wavelet bidimensionala poate fi utilizata pentru a descompune o imagine intr-un set de imagini succesive mai mici, ca in fig. de mai jos. Suma dimensiunilor ale imaginilor mai mici este aceeasi cu a imaginii originale; oricum, energia imaginii originale este compactata in imagini mici la frecventa joasa in coltul din stanga
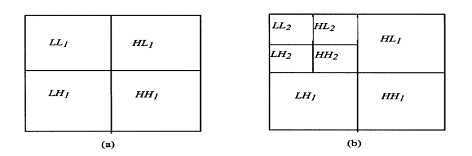
Figura 2. Descompunerea wavelet
Daca se considera un sensor de imagine pozitionat intr-o locatie tridimensionala si care achizitioneaza imagine dupa imagine, iar intr-un anumit interval de timp formanduse o secventa de imagini, Acets set de imagini poate fi reprezeinta prin intermediul unei functii de starlucire g(x,y,t), unde x zi y reprezinta coordonatele imagini in plan in plan, iar t reprezinta timpul. Referindu-ne astfel la o secvente de imagini temporale.
Daca se considera senzorul ca fiind reprezentat de un corp solid care este supus unei miscarid e translatie si de rotatie. Astfel se obtine o varietate de imagini prin translatarea senzorului in diferite punte ale planului si prin rotatii sub unghiuri diferite intr-un spatiu tridimensional. Astfel se poate imagina cum ca ar exista un numar infinit de senzori care preiau imagini din toate puntele planului tridimensional iar aceste imagin preluate de catre toti senzori formeaza o secventa de imagini spatiale. In momemntul in care are loc si o variatie a timpului se formeaza un set mult mai larg de imagini numindu-se spatiu de imagini.
Este destul de clar ca o astfel de descriere ar fi una foarte greu realizabila, chiar imposibila. In schim s-au efectuat schimbari asupra functiei de stralucire care apare sub forma:
g(x,y,t,![]() )
)
unde ![]() reprezinta pozitia senzorului in spatiul tridimensional si
avand forma :
reprezinta pozitia senzorului in spatiul tridimensional si
avand forma :
![]() =(
=(![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() )
)
unde ![]() ,
,![]() ,
,![]() reprezinta coordonatele centrului senzorului optic in
statiul 3-D, iar
reprezinta coordonatele centrului senzorului optic in
statiul 3-D, iar ![]() ,
,![]() reprezinta orientarea axelor senzorului in 3-D.
reprezinta orientarea axelor senzorului in 3-D.
Daca se presupune existenta unui punct in
P in planul 3-D care este proiect in planul imagini prin intermediul unui pixel
de coordinate xP respective yP, dar aceste puncte depinde si de t respectiv ![]() . Astfel cooordonatele pixelui pot fi scrise sub forma xP=xP(t,
. Astfel cooordonatele pixelui pot fi scrise sub forma xP=xP(t,
![]() ) si yP=yP(t,
) si yP=yP(t, ![]() ) rezultandastfel functia de stralucire sub forma:
) rezultandastfel functia de stralucire sub forma:
g=g(xP(t,
![]() ), yP(t,
), yP(t, ![]() ),t,
),t,![]() )
)
Spatiul imagini este o colectie a tuturor
posibilitatilor date de functia de starlucire. g(x,y,t,![]() ). Fiecare imagine fiind preluata de sensor aflat intr-o pozitie particulara la un moment
dat.
). Fiecare imagine fiind preluata de sensor aflat intr-o pozitie particulara la un moment
dat.
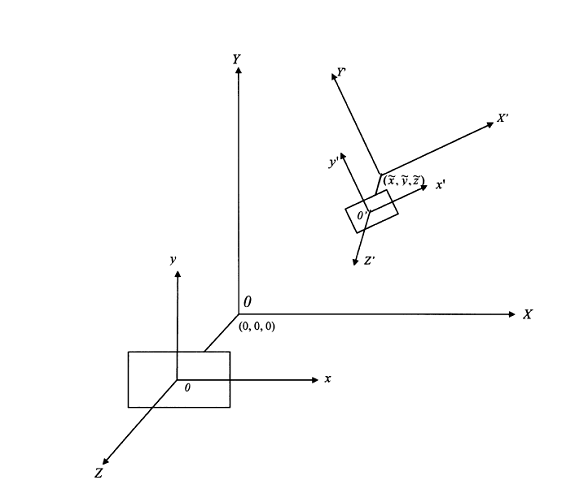 Figura
3. Pozitia senzorului
Figura
3. Pozitia senzorului ![]() =(0,0,0,0,0) si
=(0,0,0,0,0) si ![]() =(
=(![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() )
)
Toate tehnicile de compresie prezentate anterior se poat aplica in cadrul compresiei
video. Prima clasa care este si ce mai directa din punct de vedere a compresiei video este cea care presupune codarea individuala a cadrelor. Un exemplu il reprezinta codarea motion JPEG, procedeu in care se codeaza in mod individual fiecare cadru. In cea de-a doua clasa intra metodele utilizate in cadrul compresiei imaginilor dar extinse catre spatiul 3-D (DCT). S-a demonstrate ca aplicarea transformatei cosinus directa (DCT) in spatiului 3-D este una foarte eficcinta. Prin combinarea tehnici DCT impreuna cu cea de DPCM (modulatia diferentiala in cod de impulsuri) conduce la o compresie video buna. Cea de-a 2-a tehnica presupune gruparea cardrelor impreuna fata de prima care presupunea codarea individuala a cadrelor. Compresia video se diferentiaza de compresia imaginilor prin anumite caracteristici. Difernta majora o constitue corelatia intre cadre care apare in cadreul secventelor video, fata de corelatia din interiorul cadrelor care apre in cadrul corelatiei in imagini. Corelatia intre cadre mai poarta denumirea de redundanta temporala iar corelatia in interiorul cadrelor poarta numele de redundanta spatiala. Pentru a ajunge la o rata de compresia foarte buna trebuie mai intai eliminate aceste redundante dar aceasta se poate face odata cu intelegerea lor.
Daca se presupune ca se utilizeza o camera aflata pe un suporta static, camera luand imagini ale cadrului respective cu un anumit timp intre cadre. Daca in cadrele preluate de senzor nu exista schimbari majore, imaginile preluate vor avea anumite zone comune.
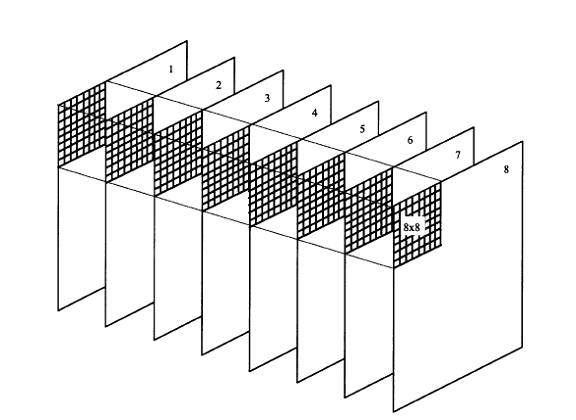
Figura 4. Zona comuna intr-o secventa de cadre
Asfel se explica existenta unei corelati intre cadre in care anumite zone in care pixeli nu isi schimba valoare pe parcursul mai multor cadre. Profitand de acest aspect se poate aplica si modulatia diferentiala in cod de impulsuri (DPCM), care presupune o codare predictive. Porniind de un prim cadru care se ia la momentul t1 apoi la un moment t2 se ia un al doilea cadru se face o analiza a diferentelor intre cele doua cadre si se extrage o functia matematica care exprima modificarile survenite de la un cadrula la altul. Pe baza acestei functi se poate face o codare predictive a cadrelor trimitandu-se doar diferenta intre cadrul preluat si cel preconizat economisindu-se spatiu de stocare si implicit timpul de prelucare diminuandu-se.
Devine clar ca aceasta a 2 metoda este una mult mai eficinta decat prima si prin prisma utlizari DCT in 3-D care presupune compactizarea zonelor de energie mare in zonele temporale de frecventa redusa
Tehnica de inlocuirea cadrelor este descrisa in randurile de mai jos ca apoi sa se faca o analiza mai amanuntita a acestei tehnici cu implicatiile, avantajele si dezavanmtajele acesteia.
Fiecare pixel din cadru este este inclus intr-una din categoriile modifocat sau nemodificat pe parcursul cadrelor care sunt achizitionat de senzorul optic. Aceats decizie de al include in una dincele 2 arii se bazeaza pe o analiza a intensitati pixelului. Astfel daca valoare intensitati pixeliului p(xi,,yi) se incadreaza intr-un anumit interval in care se ia decizia ca valoarea sa rama neschimbata fata de cadrul anterior se va incadra in categoria nemodificat in schimb daca valoara intensitatii pixelului p(xi,,yi) depaseste pragul inferior sau superior al acelui interval ea va fi incadrata in categoria de modificata. In urma acestor decizii de a se afla in una din cele doua categorii se transmite sau nu mai departe noua valoare care va fi memorata int-un buffer inlocuind vechea valoare sau daca valoare intensitati ramane inclusa incadrul intervaluluii in care se ia decizia de a il include in categria de nemodifiact se va transmite doar informatia corespunzatoare informari ca valoare nu a fost modificata iar vechea valoare pastrandu-se.
Tehnica de reumplere prezinta avantajul ca va coda doar acele valori ale intensitati care nu vor fi incluse in categoria modificat, intre cadrele successive.
Dezavantajul acestei tehnici de reumplere il constitue procedura greoaie de manevrare a secventelor de cadre atunci cand acestea se desfasoara cu o viteza prea mare, procedura care consta in transmiterea informatiilor care sa indice daca au survenit modificari si daca sa se tina cont de ele. In momentul in care se achizitioaneaza cadre cu o viteza mare au loc si modificari rapide ale nivelelor de intensitate ale pixelilor din secventa video. O solutie ar fi aceea de marirea pragurilor intervalului care indica faptul ca nu a survenit nicio modificare, dar acest lucru ar conduce in mod clar la o deteriorare a imagini.
Acest argument fiind unul extreme de solid si cantarind extreme de mult in alegerea unui procedeu mult mai evoluat de compresie fata de acesta de reumplere a cadrelor.
Aceasta tehnica se bazeaza pe o presupunere a miscarii. Miscarile survenite in interiorul cadrelor succesive sunt considerate ca fiind obiecte in miscare in planul imagini, astfel estimandu-se in prima faza vectori de deplasare. Diferenta de semnal intre valoarea intensitati pixelilor din zona de miscare si cele din aceeasi parte dar in cadrul de la pasul anterior este codata. Acest lucru a condus la o noua tehnica de codarea predictive a compensari de miscare si s-a dovedit a fi cu mult mai eficienta decat tehnica bazata pe predictia diferentei intre cadre.
Pentru o intelegere mult mai buna se
considerea analiza urmataorei imagini : 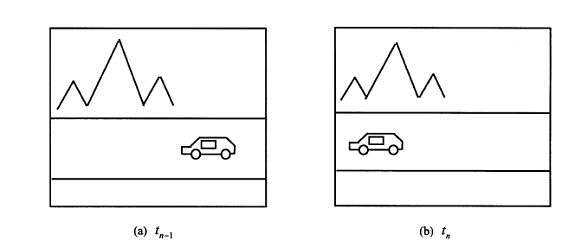
Figura 5. Secventa de cadre cu zone statice si sone in miscare
Daca se presupune faptul ca masina se deplaseaza cu o anumita viteza, aceasta este reprezenta in planul imagini printr-o translatie de la dreapta la stanga cu o viteza uniforma care exprima durata de timp intre cele doua cadre consecutive, in imagine ne mai survenind nicio I schimbare.
Daca se cunoaste vectorul de miscare al regiuni care incadreaza masina si timpul intre doua cadre successive se poate face o astfel o predicntie a pozitiei in care se va afla masina in urmatorul cadru. Din punct de vedere teoretic se poate spune ca daca vectorul de translatie este bine determinat se poate face si o predictie cat mai buna a pozitiei obiectului. In realitate insa intervin anumite erori in determinarea vectorului de miscare aceste erori putand fi generate de o variatie a zgomotului din cadre. Aceste erori conducand la predicti eronate.
Pentru a putea avea la receptie o calitate buna a cadrelor se poate extrage eroare de predictie prin urmatorul procedeu: se calculeaza predicita pentru cadrul current pe baza cadrului trecut apoi se preia cadrul current si se compara cadrul prezis cu cel current obtinandu-se eroare de predictie. Daca se codeaza vectori de deplasare si eroare de predictie si se transmite catre receptor se poate obtine astfel o recosntructie a imagini de buna calitate.
Compresia video a compensari de miscare a devenit un elelment major in dezvoltarea codarii video. Din punct de vedere functional aceats a fost impartita in 3 suseturi astfel:
analiza miscarii;
predinctia si diferenta ;
 codarea.
codarea.
Plecand de la cercetarile efectuate de catre psihoanalisti, neurofiziologisti , fizicieni asupra ochiului uman, cat si al animalelor s-a ajuns la concluzia ca perceptia miscari se imparte in 2 cai: masurare si interpretare.
Plecand de la aceste interpretari ale miscarin in perceptia vizuala in domeniul tehnic miscarea a fost impartita si ea in 2 subseturi. In primul subset intre variabilel intermediare care sunt derivate, variiabile care reprezinta paramentri miscarii in palnul imagini in 2-D. In cel de-al doilea subset intra variabilel miscarin in 3-D cum ar fi viteza, deplasarea, pozitia.
Pe baza rezultatelor intermediare, toate aproprierile catre analiza miscari pot fi impartite in 2 categorii: corespondente viitoare si flux optic. In prima intra cele cateva elemente distinte care sunt extrase din imagine, ca in exemplu de mai jos se pot considera ca elemente distincte varful botului avionului, varful cozi si varfetele aripilor. Apoi trebuie ca sa se stabilizeze aceste corespondente in cadrele care vor urma. Iar in cel de-al doilea pas miscarea in 3_D poate fi analizata pe baza acestor corespondente.
Aceste variabile intermediare intra in ultima categorie si reprezinta fluxul optic. Un vector de flux optic este definit ca un vector de viteza al tuturor pixelilor din imagine. In prima faza vectorul flux optic este determinat din secventa de imagini ca o variabila intermediare iar apoi in cel de-al doilea pas este estimate miscarea 3-D din fluxul optic. De remarcat faptul ca vectorul flux optic se refera la vectorul de deplasare, in care prin multiplicarea vectorului de viteza cu intervalul de timp care este cunostcut intre 2 cadre successive se obtine vectorul de deplsare.
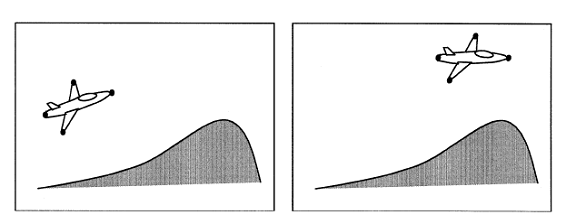
Figura 6. Calcularea vectorului de miscare intre doua cadre succesive
Standardul MPEG-4 (ISO/IEC 14496) a fost introdus in 1998 si grupeaza o serie de metode de compresie a datelor audio si video in format digital. MPEG-4 este folosit in compresia audio-video pentru web(streaming), CD, telefonie, videoteleconferinte si pentru televiziune. MPEG-4 contine multe dintre caracteristicile standardelor MPEG-1 si MPEG-2.
Standardul MPEG 4 ofera un set de tehnologii pentru a satisface nevoile autorilor, furnizorilor de servicii de retea si a utilizatorilor obisnuiti. Pentru autori, MPEG 4 permite producerea de continut multimedia care poate fi refolosit mult mai usor, are o flexibilitate mai mare decat s-a oferit pana acum prin intermediul unor tehnologii individuale cum ar fi televiziunea digitala, grafica animata, paginile de web si extensiile acestora. Prin facilitatile oferite este mai usoara protejarea drepturilor de autor asupra continutului. Pentru furnizorii de servicii de retea standardul ofera informatie sub o forma transparenta care poate fi tradusa si interpretata in mesaje specifice diferitelor retele pentru a asigura un transport optimizat in retea. Pentru utilizatorii obisnuiti MPEG 4 aduce un nivel mai ridicat de interactiune cu continutul media, in limitele stabilite de autor. Redarea continutului este posibil in cadrul unei game largi de retele, inclusiv cele cu o rata de transfer mai scazuta.
MPEG-4 are mai multe parti, insa de interes pentru lucrarea de fata sunt doar partea a 2-a (Advanced Simple Profile) si partea a 10-a (Advanced Video Coding).
Partea a 2-a din standardul MPEG-4 este o tehnologie de compresie video. Foloseste Transformata Cosinus Discreta pentru compresia datelor, intr-un mod asemanator cu standardele precedente MPEG-1 si MPEG-2. Pentru a adresa gama larga de aplicatii variind de la calitate redusa si rezolutie joasa la banda larga si rezolutie inalta, au fost create mai multe profile. MPEG-4 Part 2 are aproximativ 21 de profile, printre care se regasesc Simple, Advanced Simple, Main, Core, Advanced Coding Efficiency, Advanced Real Time Simple etc. Cele mai folosite profile sunt Advanced Simple si Simple, care este un subset al profilului Advanced Simple.
Profilul Simple este orientat spre aplicatiile unde rata de bit redusa si rezolutia joasa sunt cerute de latimea de banda de a retelei. In aceasta categorie intre telefoanele mobile, camere de supraveghere si videoteleconferinta.
Profilul Advanced Simple include suport pentru cuantizarea in stilul MPEG, suport pentru semnal video intretesut, suport pentru cadrele B, compensarea miscarii cu precizie de sfert de pixel si compensarea miscarii globale.
Cunoscut si sub numele de H.264 sau MPEG-4 AVC, acest standard ofera compresie bazata pe compensarea miscarii la nivel de bloc. El a fost dezvoltat cu scopul de a oferi o calitate video buna la o rata de bit mica comparativ cu standardele anterioare(mai putin de jumate din rata de bit necesara pentru MPEG-2 sau MPEG-4 Part 2) . Cresterea complexitatii este destul de mica astfel incat implementarea este practica. Un alt scop a fost oferirea unei flexibilitati suficient de mari astfel incat standardul sa poata fi folosit intr-o gama larga de aplicatii(telefonie, DVD, rate de bit varaibile, rezolutii joase si inalte).
H.264 contine o serie de caracteristici ce ii permit sa comprime semnalul video mult mai bine decat standardele precedente:
- Predictia inter-cadre folosind mai multe cadre: se folosesc cadrele anterioare codate ca referinte permitand astfel pana la 16 cadre referinta.
- Compensarea miscarii folosind blocuri de dimensiune variabila(de la blocuri mari de 16x16 pana la blocuri mici de 4x4). Se pot folosi si blocuri de 8x4 sau 16x8.
- Abilitatea de a folosi mai multi vectori de miscare pe macrobloc.
- Abilitatea de a folosi orice tip de macrobloc in cadrele de tip B.
- Interpolarea in 6 puncte pentru predictiile la jumatate de pixel.
- Vectori de miscare cu precizie de sfert de pixel
- Predictia spatiala pornind de la marginile blocurilor adiacente folosind un bloc de 16x16, 8x8 sau 4x4 pixeli.
- Transformari folosind numere intregi, transformarea Hadamard pentru DC.
- Filtre pentru eliminarea artefactelor include in codor.
O camera HDTV poate genera un semnal
necomprimat la o rata de pana la 149.299.200 de octeti pe
secunda(1920x1080x24x3). Acest semnal trebuie comprimat pentru a intra in
latimea de banda disponibila canalelor TV. Datorita redundatei din imagini
putem comprima semnalul astfel incat sa obtinem o rata de bit mult mai redusa.
De exemplu, culoarea cerului este
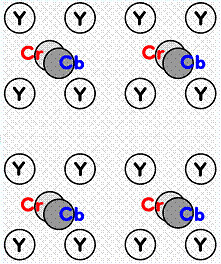
Figura 7. Subesantionarea componetelor de culoare
spatial RGB in spatial YCrCb. Obtinem astfel o componenta de luminanta(Y) si doua componente de culoare (Cr si Cb). Deoarece ochiul uman este mai putin sensibil la nuantele culorilor decat la intensitatea luminoasa, se subesantioneaza cele doua componente de culoare(Figura 7). Dupa aceea se face compresia cadrelor. Standardul MPEG-4 precizeaza trei tipuri de cadre de compresie: cadre codate intern(I-frame), cadre codate predictive(P-frame) si cadre codate predictive bidirectional(B-frame). Exista si un al patrulea tip de cadru(D-frame) in care se retine doar componenta continua din fiecare bloc si este folosit doar pentru parcurgerea rapida prin secventa comprimata. Cadrele I folosesc o compresie asemanatoare cu cea de la JPEG folosind blocuri de macroblocuri de pixeli. Compresia acestor cadre nu depinde de alte cadre. Cadrele P depind de cadrele I si pot contine intrablocuri sau blocuri estimate. Cadrele B depind de cadrele I si P si pot contine intrablocuri, blocuri estimate si blocuri estimate bidirectional.
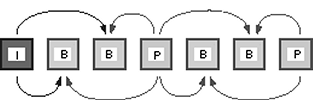
Figura 8. Predictia cadrelor
Macroblocurile folosite pentru predictia cadrelor au dimensiunea de 16x16 pixeli. Pentru fiecare macrobloc din imaginea curenta se determina un vector de miscare fata de un bloc de referinta. Eroarea dintre blocul estimat si blocul curent este codata folosind Transformata Cosinus Discreta.

Figura 9. Estimarea miscarii pentru un bloc
Standardul MPEG-4 nu specifica cum se calculeaza vectorii de miscare. Este specificat doar modul de codare in fluxul de date ce va fi transmis. Acest lucru inseamna ca la codare putem sa alegem un algoritm convenabil pentru determinarea vectorilor de miscare. Cele mai bune rezultate sunt date de algoritmul full-search, insa acest algoritm neceistati cantitati foarte mari de memorie si putere de calcul. Pentru a rezolva acest neasjuns au fost dezvoltati si algoritmi care sa ofere rezultate asemanatoare insa resursele folosite sa fie mult reduse.
Cautarea logaritmica porneste de pozitia curenta si cauta in 4 puncte pe orizontala si pe verticala. Acest pas se repeta de mai multe ori si astfel se obtine vectorul de miscare(Fig 10).
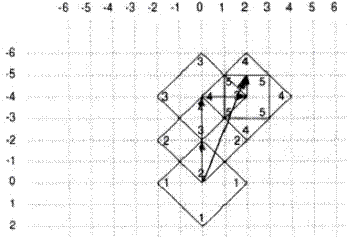
Figura 10. Algoritmul de cautare 2D logaritmic.[11]
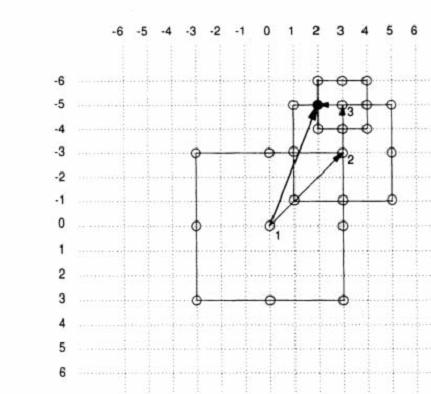
Figura 11. Algoritmul de cautare in 3 pasi [11]
Algoritmul de cautare in 3 pasi este asemanator cu algoritmul de cautare logaritmic insa vecinatatea in care se cauta vectorii de miscare se reduce la fiecare pas.
Experimentele au fost rulate folosind 2 filme de test: foreman.yuv si coastguard.yuv. Formatul fisierelor folosite a fost YUV 4:2:0 RAW. S-au estimate vectorii de miscare doar pe commponenta de luminanta. Am testat comparativ doi algoritmi de cautare a vectorilor de msicare: full-search si 3-step search. In urma testelor am observat ca algorimul de full-search are PSNR-ul cu 1-2 dB mai bun decat algoritmul 3-step search. Insa aceasta crestere a calitatii se obtine folosind o putere de calcul mult mai mare. Full-search pe +/- 4 pixeli este de 2-3 ori mai lent decat 3-step search iar full-search pe +/- 8 pixeli este de 10-11 ori mai lent. La ambii algoritmi PSNR-ul imaginilor a avut un scor mai mare de 30 dB. Putem trage concluzia ca imaginile au avut o calitate intre acceptabila si buna. De asemenea trebuie sa remarcam viteza ridicata a algoritmului 3-step search ceea ce il face util in aplicatiile embedded unde puterea de calcul este destul de redusa(telefoane cu inregistrare video, camere video).
De asemenea putem observa o crestere a PSNR-ului o data cu micsorarea blocului folosit pentru estimarea vectorilor de miscare deoarece se face o potrivire mai buna a marginilor obiectelor aflate in miscare.

Figura 12. Vectori de miscare corelati (se observa ca fundalul
se misca mai lent decat persoana din prim-plan)

Figura 13. Vectori de miscare necorelati
datorita miscarii ample a imaginii
Calcularea ratei de compresie considerand ca facem o transmisie cu 2 tipuri de cadre: integral si estimat (alternativ). Pentru cadrul estimat avem vectori de miscare pentru distante de +/- 16. Amplitudinea o stocam pe 4-5 biti si semnul pe 1 bit. Folosind 5-6 biti pentru fiecare directie (X si Y) ajungem sa transmitem doar 10-12 biti pentru un bloc de 16*16 pixeli de luma. Cantitatea originala de informatie era 16*16*8 = 2048 biti. Stiind ca transmitem un cadru original si un cadru estimat, ajungem sa transmitem 2048+12 biti pentru 2 cadre. Facand un raport intre cantitatea de date originala si cantitatea de date transmisa obtinem (2048+12)/(2048+2048). Observam ca astfel putem reduce cu 49,7% cantintatea de date transmisa. In realitatea, mai sunt transmise si erorile de estimare pe canalul de date, insa cantitatea de date transmisa este mult redusa prin folosirea compresiei bazata pe estimarea miscarii blocurilor.
|
|
F8B16 |
F8B8 |
F8B4 |
F4B16 |
F4B8 |
F4B4 |
||||||
|
|
dB |
ms |
dB |
Ms |
dB |
Ms |
dB |
ms |
dB |
Ms |
dB |
ms |
|
F |
33.7 |
726 |
35.7 |
760 |
37.8 |
838 |
33 |
192 |
34.7 |
203 |
36.6 |
239 |
|
C |
31.8 |
704 |
32.2 |
755 |
33 |
824 |
31.9 |
202 |
32.2 |
212 |
32.9 |
233 |
Tabelul 1. PSNR pentru metoda full search pentru distante +/- 8 si +/- 4.
|
|
3S16 |
3S8 |
3S4 |
|||
|
|
dB |
Ms |
dB |
ms |
dB |
Ms |
|
F |
33 |
72 |
34.3 |
72 |
35.64 |
79 |
|
C |
31.87 |
72 |
32 |
72 |
31.8 |
80 |
Tabelul 2. PSNR pentru metoda 3-Step search
F - Foreman
C - Coastguard
FxBy - Full search +/- x with block y*y
3Sy - 3-Step search with block y*y
Algoritmii de compresie video folosesc metode diverse pentru a compresa informatia din semnalul video. Daca in cazul 2D se foloseste frecvent transformata cosinus discreta(JPEG), in cazul semnalului video s-au introdus noi metode de compresie bazate pe redundanta temporala existenta in semnalul transmis. Una din metodele cel mai des intalnite este compresia bazate pe estimarea miscarii blocurilor din cadrul imaginilor. Aceasta metoda a aparut la mijlocul anilor '80 odata cu dezvoltarea echipamentelor digitale. Dezavantajul acestei metode este cantitatea foarte mare de putere de calcul necesara pentru obtinerea vectorilor de miscare corecti. Acest dezavantaj a fost ameliorat prin folosirea unor algoritmi care desi nu garanteaza obtinerea vectorilor de miscare optimi, necesita o putere de calcul redusa.
De asemenea, rezultatele experimentale ne arata ca folosind vectorii de miscare putem obtine o compresie destul de ridicata a semnalului. Estimarea corecta a vectorilor de miscare va duce la o cantitate de erori foarte mica si la o rata de compresie destul de ridicata.
Pe viitor se vor dezvolta algoritmi ce vor face compresie bazata pe obiectele din imagine. Se va descompune fiecare cadru intr-un set de obiecte aflate pe un fundal anume si se va realiza o compresie individuala. Acest lucru va permite ca obiectele de interes dintr-o scena sa fie compresate la o calitate superioara iar obiectele care fac parte din decor sa fie compresate puternic(la o calitate mai slaba).
[1] https://en.wikipedia.org/wiki/MPEG-1
[2] https://en.wikipedia.org/wiki/MPEG-2
[3] https://en.wikipedia.org/wiki/Advanced_Video_Coding
[4] https://en.wikipedia.org/wiki/MPEG-4
[5] https://en.wikipedia.org/wiki/Advanced_Simple_Profile
[6] https://en.wikipedia.org/wiki/Discrete_Cosine_Transform
[7] https://en.wikipedia.org/wiki/Huffman_coding
[8] https://en.wikipedia.org/wiki/Wavelet
[9] https://en.wikipedia.org/wiki/Vector_quantization
[10] https://en.wikipedia.org/wiki/Run-length_encoding
[11] MPEG Video Compression Standard - Joan L. Mitchell et al.
