METODE DE COMPARATIE PENTRU 2 ESANTIOANE PERECHI
Se lucreaza pe diferente
![]() =
= ![]() md
- media diferentelora
md
- media diferentelora
daca acceptam Ho T md = 0
![]() =
= 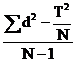 T = ad
- tabel cu d, ad, d2, ad2
T = ad
- tabel cu d, ad, d2, ad2
![]() =
= ![]()
df = N - 1
1. Esantioane perechi
Un cercetator a efectuat un experiment privind iluziile; el a vrut sa vada daca pozitionarea obiectului influenteaza aprecierea cercetarii. In acest scop a iluminat acelasi obiect cu o sursa de lumina pozitionata in fata obiectului si apoi deasupra lui si a cerut unui lot de 10 subiecti sa aprecieze dimensiunile obiectului in fiecare dintre cele doua cazuri.
A obtinut urmatoarele rezultate, luand in studiu 10 subiecti (perechi).
|
Subiecti |
Inainte |
Deasupra |
d |
d2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ad = 19 |
ad2 = |
Identificarea variabilelor
VI: A - pozitia obiectului
a1 - inainte
a2 - deasupra
VD: X - dezvoltarea (operationalizata prin scoruri)
Design experimental: de baza intragrup
|
A |
a1 |
a2 |
|
VD |
|
|
Tip de esantion - esantioane perechi
Formularea ipotezelor
Ipoteza specifica Hs
Exista diferente semnificative in aprecierea dimensiunilor obiectului in functie de pozitia acestuia.
Ipoteza nula (atribuita hazardului)H0:
Diferentele aparute in aprecierile dimensiunii obiectelor in functie de pozitia lor se datoreaza hazardului (intamplarii)
Se lucreaza pe diferente (fie dreapta minus stanga, fie stanga minus dreapta, respectam regula)
Vom face sumele in valoare absoluta cand le ridicam la patrat; in rest, calculam sumele algebrice.
![]() = ; T = ad
= ; T = ad
![]() =
= 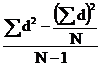 ;
; ![]() = 4,3
= 4,3
![]() =
= ![]() ;
; ![]() =
=![]() = 1,9
= 1,9
![]() =
= ![]() ;
; ![]() =
= ![]() = 0,44
= 0,44
Calculam numarul gradelor de libertate
df = N -1; df = 10 - 1 = 9
|
p |
|
|
|
|
t calc. = 0,44
Interpretare
Intrucat valoarea calculata a lui t de 0,44 este mai mica decat valoarea critica la pragul de 0,05 egala cu 2,262, sansele ipotezei nule sunt mai mari de 5%, suspendam decizia.
Pentru a realiza calculele pentru testul t perechi in programul SPSS 15.0
Astfel, prima data cream baza de date, prin definirea variabilelor in fereastra Variable View si introducem valorile in fereastra Data View.

Verificam distributia datelor cu ajutorul testului Kolmogorov - Smirnov, si constatam ca datele au o distributie simetrica la nivelul populatiei din care a fost extras esantionul experimental.
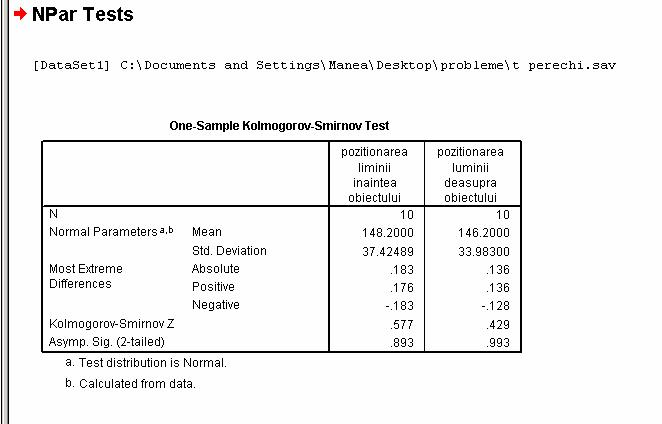
Dupa care alegem testul statistic, in cazul nostru testul t pentru esantioane perechi, si introducem variabilele asa cum apare in ferestrele de mai jos.
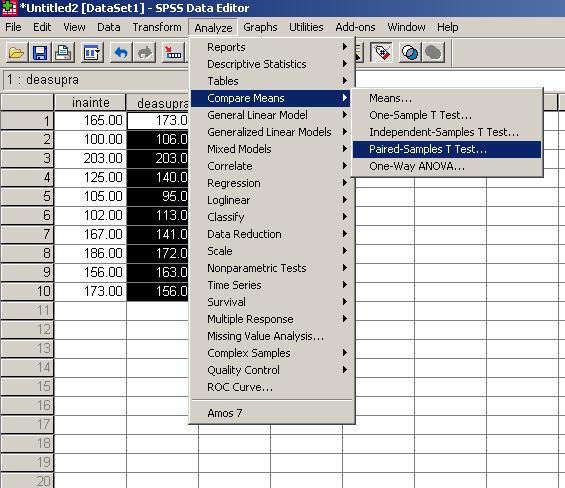
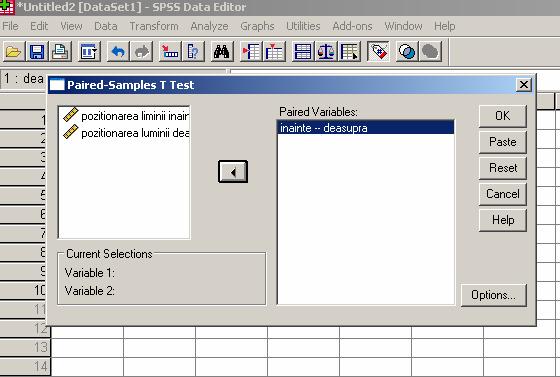
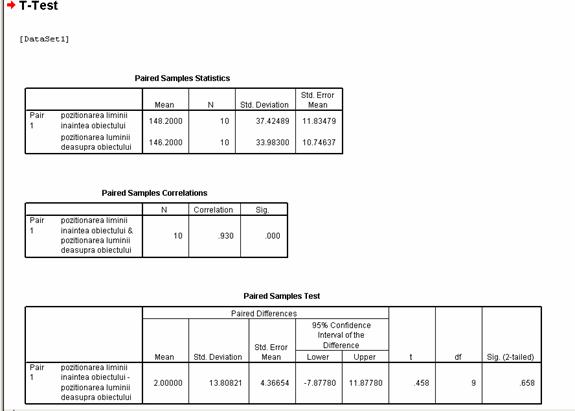
Prin urmare obtinem analiza descriptiva a datelor, si rezultatele testului statistic.
Valoarea testului t = .458 la un prag de semnificatie p= .658, mai mare decat pragul critic p = .05, ceea ce afirma ca nu se obtin diferente semnificative intre cele doua conditii experimentale, sansele ipotezei nule sunt mai mari de 5%, suspendam decizia.
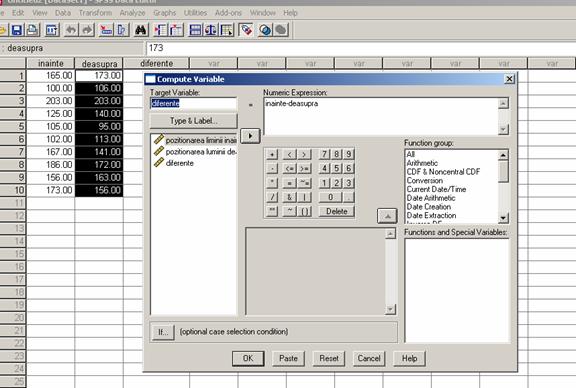
Pentru calcularea diferentelor dintre cele doua testari ale subiectilor vom folosi functia de Compute Variable din comanda Transform a meniului principal al programului. Vom introduce prima variabila - variabila a doua.
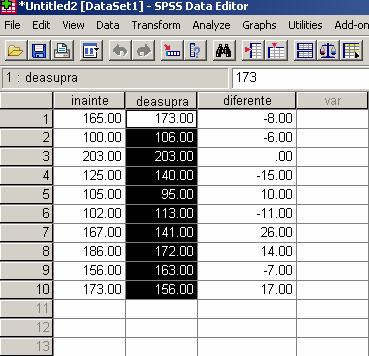
Astfel, diferenta va aparea in baza de date ca si o variabila noua.
La fel se procedeaza si cu diferenta ² numai ca de data asta o sa introducem d * d.
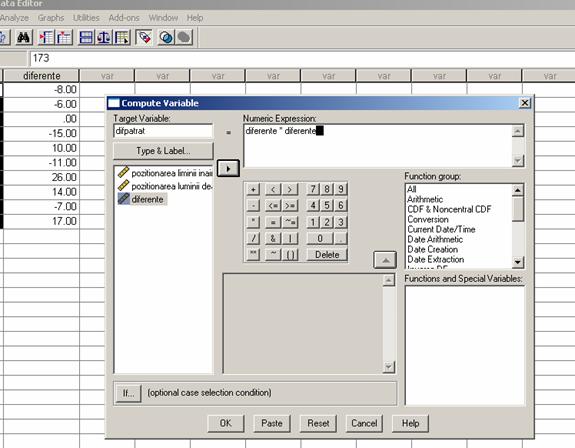
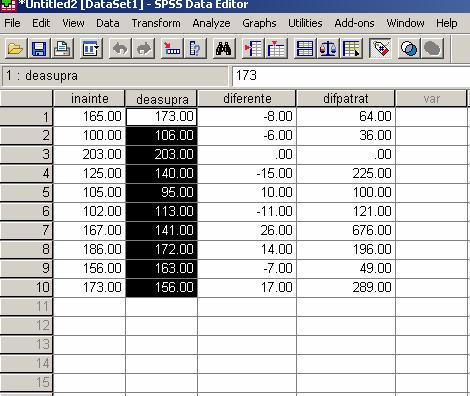
Finalul tabelului va aparea ca si in ecranul de mai sus.
Chi scuare-testul χ2
Acest test statistic se utilizeaza cand datele obtinute sunt sub forma de frecvente adica atunci cind procedurile de masurare au la baza scale nominale sau ordinale.
Un exemplu de astfel de experiment este cel efectuat de Mc Minn(1994) (apud Meyers si Hausen, 2003). Autorii au dorit sa verifice daca este posibil sa amelioreze prin antrenament indentifiacrea unui limbaj sexist. Pentru aceasta ei au utilizat un grup care este antrenat in recunoasterea limbajului sexist si un grup de control care nu a aparticipat la antrenamente.
Subiectilor din cele doua grupuri li s-a cerut sa identifice din text itemi care contin un limbaj sexist.Din totalul itemilor care trebuiau evaluati 9 contineau un limbaj sexist.Rezulatele obsinute prin utilizarea lui χ2 au aratat ca antrenamentul are un efect important pe ansamblul celor 9 itemi, aproape toti subiecsii au comis erori asupra recunoasterii itemilor in ciuda exercitiului.
Pentru a aplica χ2 , trebuie sa incepem cu prezentarea datelor sub forma unei matrici de tip 2x2, unde frecventele de aparitie a comportamentelor sunt indicate in casutele tabelului.
Demersul testarii H0 aici porneste de la compararea frecventelor obsinute in experiment ( numite frecvente observate-notate cu O) cu frecventele asteptate sau expectate la nivel de populatie numite frecvente teoretice-notate cu T.
Ipoteza nula H0 aici spune ca frecventele observate nu sunt diferite de frecventele asteptate la nivel de populatie, adica frecventele teoretice_altfel spus O=T.
Daca χ2 este semnificativ putem respinge H0.
Daca avem doua grupuri de subiecti ca si in cazul de fata, statistica recomandata - tinand cont de faptul ca datele sunt sub forma de frecvente este χ2 iar numarul minim de subiecti din fiecare casuta a tabelului trebuie sa nu fie mai mic de 5.
Pentru matricile de tip 2x2 calulul lui χ2 este usor de facut .Pentru aceasta insa trebuie sa calculam frecventa teoretica pentru fiecare din cele 4 cazuri ale tabelului de contingenta.
Frecventele teoretice se calculeaza pornind de la frecventele observate aplicand formula urmataoare:
T=(totalul pe linie)x(totalul pe coloana)/N
Unde N reprezinta numarul total de subiecti luati in studiu.
Aici numarul total de subiecti luati in studiu este N =40 iar frecventele teoretice sunt trecute in casutele tabelului intre paranteze.
TabelulCalculul lui χ2 -exemplu
|
|
Rezultatele studiului |
|
|
|
|
corecte |
gresite |
total |
|
Grup supus intruirii |
|
|
|
|
|
|
|
|
|
Grup de control |
|
|
|
|
|
|
|
|
|
Total |
|
|
N=40 |
T=20x25 T=12.5
Avand deja frecventa teoretica putem calcula valoarea
χ2 =Σ ( O-T)2/T
χ2obt=24. Problema care se pune este : Aceasta valoare este suficient de mare pentru a putea spune ca exista diferente semnificative intre cele doua grupuri?
Acest lucru il putem stabili prin raportare la valoarea critica, adica valoarea minima necesara care sa ne permita sa afirmam ca intre cele doua grupuri exista diferente semnificative cu un risc minim asumat.
Aceste valori critice le vom citi dintr+un tabel special insa pentru a putea realiza acest lucriu trebuie sa cunosttem numarul gradelor de libertate.
Numim grade de libertate numarul de clasde dintr-o distributie pentru care efectivele pot varia liber fara a se schimba pentru a aatinge o valoare statistica deja cunoscuta ( total sau in medie fixata) de clase ale distributiei.
Esantioane de aceeasi marime pot avea grade de libertate diferite in functie de conceptia experimentala si statisticile utilizate.
Altfel spus, gradele de libertate reprezinta numarul de clase dintr-o distributie pe care le putem schimba fara ca acestea sa altereze valoarea medie.
Gradele de libertate ale unei distributii depind de statisticile utilizate si numarul de subiecti dintr-un esantion.
In cazul de fata numarul gradelor de libertate:
Df (ν)=(numarul de linii -1)x(numarul de coloane-1)
Df=(2-1) x (2-1)=1.
In conditia data valoarea critica pentru a respinge ipoteza nula este 3.84.
|
p |
|
|
|
|
|
|
|
|
In cazul nostru valoarea obsinuta χ2=24 este superiaora valorii critice la pragul de p=o.o5 care este χ2critic=3.83, deci sansele Ho sunt mai mivci de 5%, ceea ce ne face sa dam credit Hs..
Sistematizand putem spune:
Ipoteza de cercetare a fost confiramata, sau ii dam credit, dar nu vom spune niciodata ca este "adevarata".
Asa cum prezicea ipoteza de cercetare ,o diferenta semnificativa a aparut intre conditia experimentala si conditia de control.
